
Most content marketers think about decay the same way they think about expiration dates. A page goes stale, traffic slips, you refresh it, traffic comes back. Simple.
That mental model works fine for traditional Google search. It is incomplete the moment you start optimizing for AI search.
Here is what almost nobody is talking about: Google and LLMs run on completely different decay clocks. Google measures freshness in time. LLMs measure freshness in consensus. Those two clocks can run in opposite directions on the same page, which means a piece of content can rank perfectly well in Google while being functionally invisible in ChatGPT, Perplexity, and Google AI Overviews. And the standard content refresh playbook will not always fix it.
This post walks through why these two systems age content differently, how to diagnose which clock is failing on a given page, and what to do about it.
The Two-Clock Problem
Google’s freshness signal is fundamentally about time. When Google decides how fresh a page is, it leans on temporal markers: the publish date, the last-modified timestamp, the date Googlebot last crawled the page, the dates of incoming links, the dates of citations within the content.
Google has documented its query-deserves-freshness systems directly: they exist to show fresher content for queries where recency would be expected. An updated timestamp, fresher inbound links, and a clear last-modified date can move a Google ranking even if the page’s underlying claims are unchanged. The clock is calendar-based.
LLMs do not work this way. They do not see your timestamp. They do not care when your inbound links were placed. What they care about is whether the content of your page still matches the current consensus in their training data and retrieval index.
The mechanism behind this is retrieval-augmented generation, the architecture most modern AI systems use to ground their responses in current information. When a user asks a question, the system converts the query into a vector embedding, then searches a vector database of indexed content for semantically similar chunks. The chunks that match best get pulled into the prompt and shape the generated answer.
That distinction is everything. An LLM is comparing the claims on your page against a much larger pool of claims from across its corpus. If the consensus in that pool has shifted, your page can be perfectly current in calendar terms while being completely out of step in semantic terms. The clock is consensus-based.

Why These Clocks Diverge
Three mechanisms drive the divergence. Each is worth understanding because they create different decay patterns that need different fixes.
1. LLMs absorb new consensus faster than they reflect specific updates
When a major LLM gets retrained or its retrieval index is updated, it ingests a huge volume of recent content from across the web in a relatively short window. That means new consensus positions can propagate through an LLM very quickly. If the bulk of recently published content on a topic has shifted to a new framing, the LLM’s internal representation of that topic shifts too, regardless of whether your individual page got an update.
Google works differently. It evaluates your page on its own merits relative to its query. A page that is well-linked and authoritative can hold its ranking even after the broader conversation in its space has moved on, because Google is not comparing your page to the aggregate state of the topic. The LLM is.
2. Terminology drift hits LLMs harder than it hits Google
Industry terminology shifts constantly. Twitter became X. AI search used to be called Search Generative Experience, then Google rebranded it to AI Overviews at its 2024 I/O event. Generative engine optimization sits alongside AI search optimization, answer engine optimization, and a half-dozen other labels for the same idea.
Google handles this reasonably well because it uses synonym mapping and entity resolution to understand that two different terms can refer to the same concept. A page about Twitter can still rank for X-related queries, especially with good internal links and updated mentions.
LLMs handle it less gracefully. When an LLM retrieves chunks of content to ground its response, the chunks have to semantically match the query. If your page uses 2022 terminology and the query uses 2026 terminology, the embedding distance between your content and the query can be large enough that the system never surfaces your page as a candidate. You did not lose the citation because your content is wrong. You lost it because your vocabulary is out of date.
3. The factual standard is stricter for AI citation than for ranking
Google can rank a page that contains a factual claim the rest of the web disputes, because Google is not in the business of fact-checking individual claims at query time. It is matching pages to queries.
LLMs are different. When they pull content into a generated response, they are effectively endorsing the claim. Most modern AI systems include verification steps that cross-reference claims against multiple sources. A page with an outdated statistic, a deprecated product name, or a fact that has since been superseded is much less likely to be cited, because citing it would put the LLM at risk of generating a response that conflicts with other sources in its corpus.
This means that even small inaccuracies, the kind of thing that would never affect a Google ranking, can quietly kill AI visibility on a page that is otherwise strong.
How to Spot Which Clock Is Failing
Once you accept that Google decay and LLM decay are different problems, you need a way to tell them apart. Here is the diagnostic framework we use when auditing a client’s content for AI visibility.
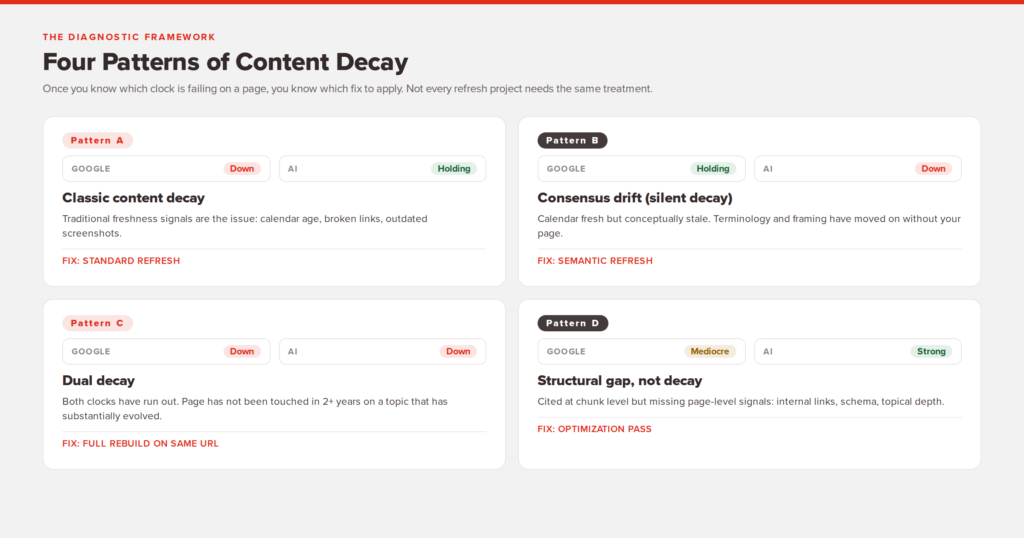
Symptom Pattern A: Google traffic dropping, AI citations holding
This is the classic content decay pattern. The page is losing position in traditional search, but it is still being pulled into AI answers. Diagnosis: traditional freshness signals are the issue. Calendar age, broken links, outdated screenshots, lack of recent updates. The standard refresh playbook will work here.
Symptom Pattern B: Google traffic holding, AI citations dropping
This is the pattern most people miss. The page is still ranking and still drawing organic visitors. But when you check it across ChatGPT, Perplexity, and AI Overviews, you are no longer showing up for queries you used to win. Diagnosis: consensus drift. Your page is calendar-fresh but conceptually stale. The fix is not new timestamps. The fix is a deep semantic update that brings your terminology, framing, and factual claims into alignment with the current consensus in your space.
Symptom Pattern C: Both dropping
Both clocks have run out. This is usually a page that has not been touched in two years or more, sitting on a topic that has substantially evolved. The temptation is to add a fresh date and call it done. Do not. A page like this needs both clocks reset, which means a structural rewrite plus a content modernization.
Symptom Pattern D: AI citations strong, Google traffic mediocre
The page is being pulled into AI answers but is not converting that into traditional ranking. Diagnosis: usually a structural or technical issue, not a decay issue. The page is being parsed and cited at the chunk level, but is missing the page-level signals Google needs. Internal links, schema, depth of coverage, topical clustering, and the E-E-A-T signals Google weights in its core ranking systems all tend to be where the gap sits.
Different Fixes for Different Decay Types
The same five-step refresh template gets thrown at every page that loses visibility, and that is part of why so many refresh projects underdeliver. Here is what actually moves the needle for each pattern.
For traditional decay (Pattern A): the standard refresh
- Update the timestamp and last-modified date.
- Refresh all statistics with current data sources.
- Audit outbound links and replace anything broken or stale.
- Update screenshots and visual examples.
- Add fresh internal links from recently published pages.
For consensus decay (Pattern B): the semantic refresh
- Audit your terminology against current AI Overview citations for your target queries. What words and phrases do the cited pages use that yours does not?
- Update any claims that have been superseded by industry shifts, product rebrands, or methodology changes.
- Add a section that addresses the most current framing of your topic, even if the older framing is still useful context.
- Restructure your answer formats to match how AI systems prefer to extract information: direct answer first, supporting context after.
- Update timestamps too, but understand that the timestamp is the icing, not the cake.
For dual decay (Pattern C): the rebuild
This is where you stop refreshing and start rewriting. The page needs new structure, current claims, modern terminology, and fresh examples. At this point, you are essentially writing a new piece of content on the same URL, which is the most powerful move you can make because you keep the page’s existing link equity and crawl history while resetting both clocks.
For structural decay (Pattern D): the optimization pass
- Audit internal linking. Pages that get cited in AI but not in Google often lack the internal link signals Google uses to assess topical authority.
- Add or update schema markup to help Google understand the entities and relationships in the content.
- Check your topical cluster. Pages in isolation underperform pages embedded in a content hub.
- Review meta titles and descriptions. AI systems work from the body content. Google still weights the title heavily.

Why This Matters Right Now
AI citation traffic is becoming a meaningful share of high-intent organic traffic for most brands, and the gap between Google performance and AI performance is widening. Pages that have been doing fine for years are quietly slipping out of the AI citation pool while their Google numbers look stable. That kind of silent decay is the most dangerous kind because it does not show up in your standard reporting until it is already a problem.
The teams that are getting ahead of this are the ones that have stopped treating content as a write-once asset and started treating it as something that needs ongoing attention from two angles: traditional freshness and semantic alignment with the current consensus.
That does not mean you need to rewrite everything every quarter. It means you need to know which pages are decaying on which clock, and apply the right fix to each.
Putting This Into Practice
If you want to know which of your pages are dropping out of the AI citation pool, HOTH AI Discover measures your visibility across ChatGPT, Perplexity, Google AI Overviews, and Gemini. It gives you a page-by-page view of where you are being cited, where the gaps are, and which queries you are losing. That is the data you need to tell traditional decay apart from consensus decay.
Once you know which pages need work, HOTH Content Refresh handles the rest. Every refresh includes at least 50 percent new content, current data and citations, AI-ready structure, and a modernized terminology pass. It is built for exactly the kind of dual-clock decay this post describes, because most refresh projects in 2026 need both calendar updates and consensus updates to actually move the needle.
For a broader read on how AI freshness signals work and how to keep evergreen content from going stale in the first place, see our deeper guide on content freshness in AI citations and our breakdown of semantic drift and content decay.
If you would rather have our team handle the audit and the refreshes for you across your entire library, book a call and we will walk through your site, identify which decay patterns are showing up where, and put a refresh roadmap together that fixes both clocks at once.
Leave a comment